Transfer learning is a paradigm of machine learning often looked at in conjunction with End to End learning. End to end learning is paradigm in machine learning where an algorithm takes inputs and desired actions, to learn a function that maps input to output. An example is an end to end autonomous driving system which takes millions of hours of car videos to learn driving. AI practitioners prefer this paradigm of machine learning because they do not have to get external expertise. Also as everything is learnt from data, there will be very little “hard coding”. There are several problems with this logic:
- It requires way too much of data
- As everything will become a black box there is no way to debug certain behavior
- Each application will have to start from scratch and cannot leverage upon learning in other applications
- Using this approach, the algorithm will only learn to respond to events that are similar to events in the training data set, it may not extrapolate well to unseen circumstances
- It requires large amount off computational power
A much better alternative paradigm is “Transfer Learning”. We humans do transfer learning all the time. For example we learn about objects and shapes since childhood. We learn about directions and road signs later in life. We learn motor skills again through our childhood. When we have to learn how to drive a car, we do not start from scratch. We use all the learning we have gained using various other activities to learn a car quickly. Because of this type of learning we don’t have to go through several thousands of hours of training. We will also be easily able to extrapolate our learning to different types of cars, different roads, different scenarios we might encounter while driving. We colloquially call this “common sense”. Transfer learning is a critical piece both for Small Data AI and Decentralized AI.
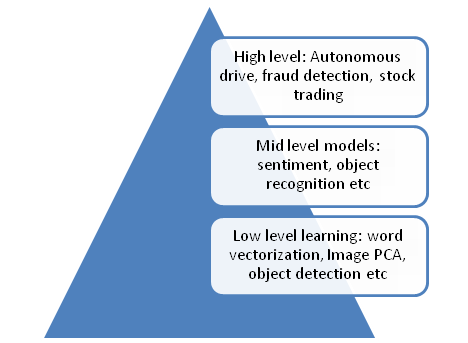
Transfer learning is already being put to use in several areas of AI. A good example of transfer learning is in text analytics using vector representations of words. Machines are better at understanding numbers than symbols. So most of natural language processing tools in AI convert text into numbers and use the numbers to derive information. If someone wants to get sentiment of a tweet they can take the numeric representation of the tweet and learn by tagging several tweets as positive or negative. So where does transfer learning come into play? For a single entity to tag millions of tweets as positive or negative and learn from that will be near to impossible. A better approach will be for one entity to build a tool to convert tweets into numbers (thus reducing the conditionality of the tweet) and another entity to use those numbers to build a sentiment model for a limited set of tweets. First entity is transferring the learning to the second entity, hence the paradigm is called transfer learning. This entity can further transfer it machine learnt model of sentiment to another entity who can use it for building marketing campaign models, so on and so forth.
This modularization of learning suddenly helps in scaling AI to massive levels. entities like Google, who scrape content across the internet can build the low level models of processing raw data. Specialized entities can build the next layer. For example layers to detect/recognize faces, get sentiment and intent from text etc. there could be higher layers who can build models for applications. These include stock market trading, fraud detection and autonomous driving.